Setting up a Trino database
Let's take a look at how you can use trino with Waii!
Prerequisites
Ensure to install the following as part of setting up your environment.
- Node.js (preferably version 20)
- Python (preferably >= 3.11.9)
- Installation | Waii CLI
- Trino docker image (Refer Appendix)
Adding a Trino Connection
In the waii UI, click on "manage warehouses" in the top right corner menu.

This should open up a window for adding new connections. Click on the "Add New" button to add a new Trino connection. You'll see the following screen:

If you want to use a JWT token to authenticate your Trino connection, you can select “JWT” as the authentication type here and enter your token in the password field.
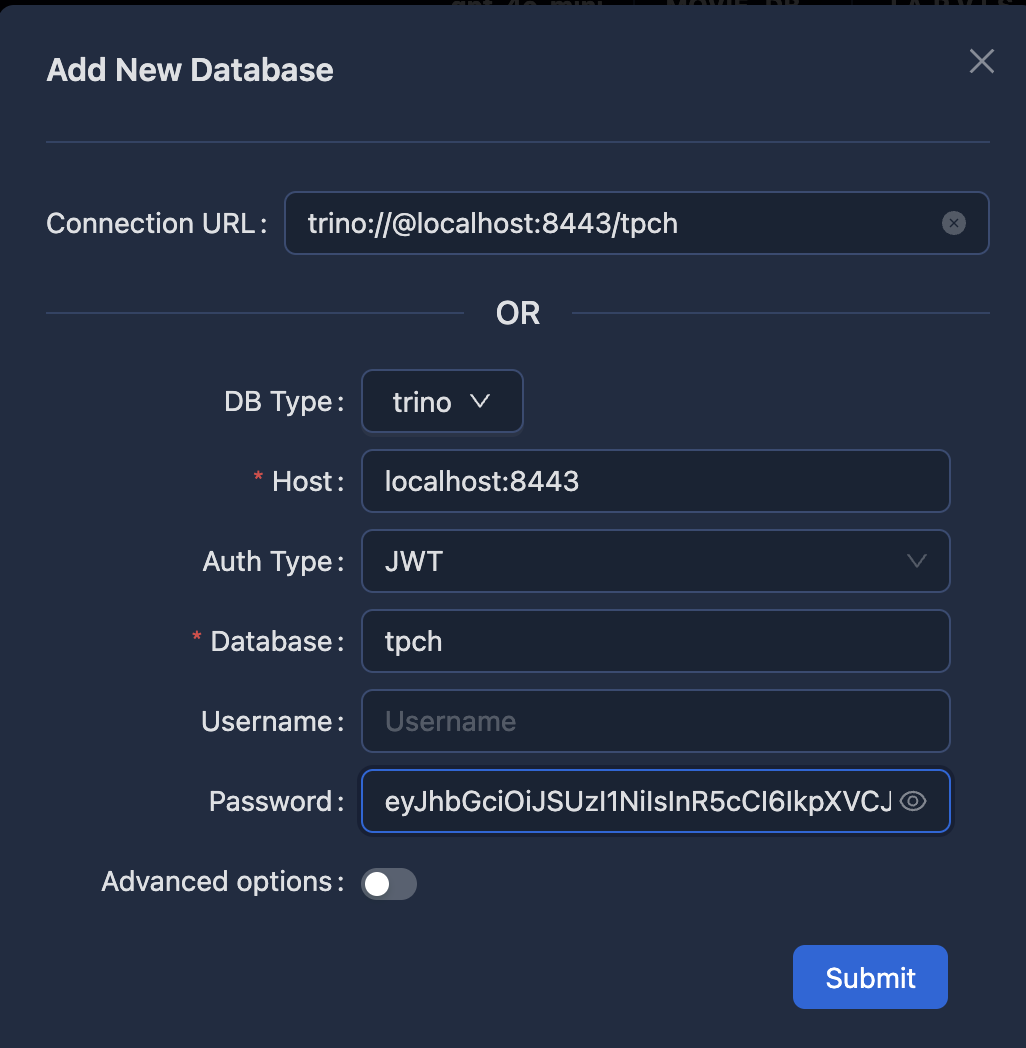
Click on submit after filling in the details. This should add a new Trino connection in Waii. It will take some time to index the entire database, as it creates and populates the knowledge graph. The following schemas will be visible after adding the connection successfully.
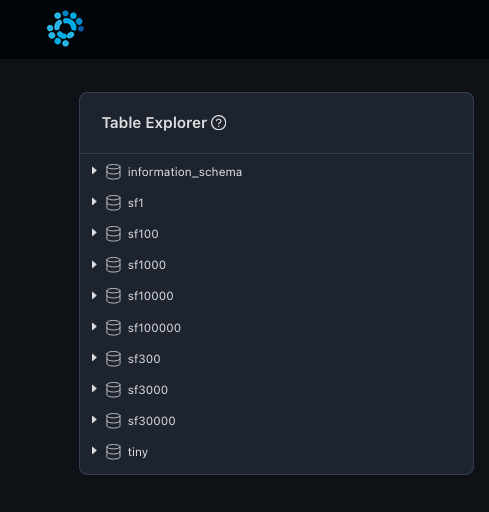
TPC-H
The default trino docker image comes with the TPC-H schema preinstalled. There are various scale factors available ranging from 1..10000. For a laptop setup, scale factor 1 will be the preferred schema. Following is the TPC-H schema extracted from the official website.

Waii's CLI can be used to view the DDL details of the tables:
waii database activate "trino://admin@localhost:8080/tpch"
waii table ddl
CREATE SCHEMA IF NOT EXISTS "tpch"."sf1";
CREATE TABLE IF NOT EXISTS "tpch"."sf1"."orders" (
"orderkey" bigint,
"custkey" bigint,
"orderstatus" varchar(1),
"totalprice" double,
"orderdate" date,
"orderpriority" varchar(15),
"clerk" varchar(15),
"shippriority" integer,
"comment" varchar(79)
);
...
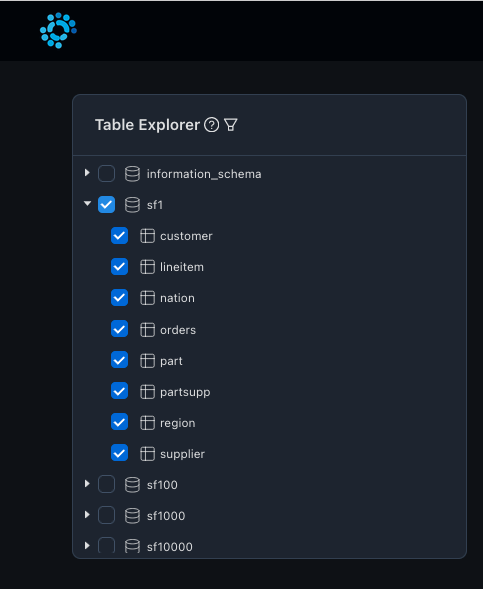
You can also view the tables in SF1 schema from the table explorer:
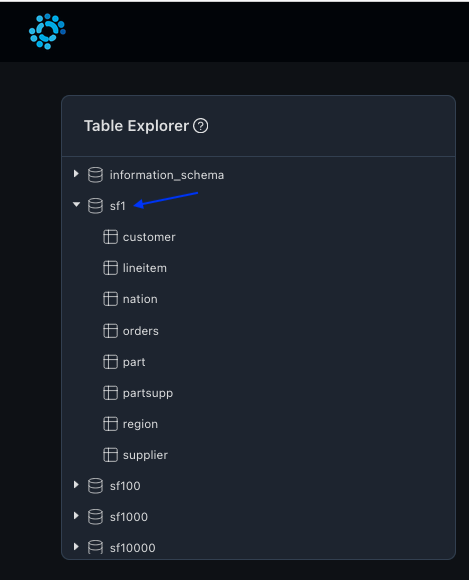
As there are multiple schemas (SF1, SF100 etc, in various scale factors), user can choose the specific schema that they are interested in. Table filters can help in choosing only the relevant schema of interest.
Using Table Filter
Table filters can be enabled by enabling the "Show table filter" option in the menu as shown in the screenshot below.
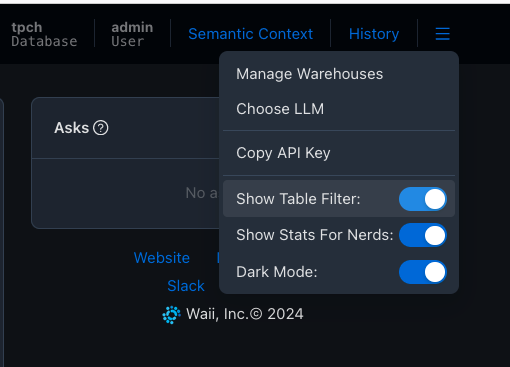
Table filter allows users to choose the most relevant schema and tables for their context. Note that metadata updates may be delayed by up to 10 minutes.
To focus only on SF1 schema, we can choose only SF1 schema via table filter.
Primary/Foreign Key Constraint validation
Join keys play a major role in query generation. Waii can gather information about PK/FK in various ways.
- By looking at the schema definitions from the database.
- Analyzing table/column descriptions and coming up with PK/FK details.
- Learn from the user provided PK/FK details. Users can provide PK/FK details via Waii API.
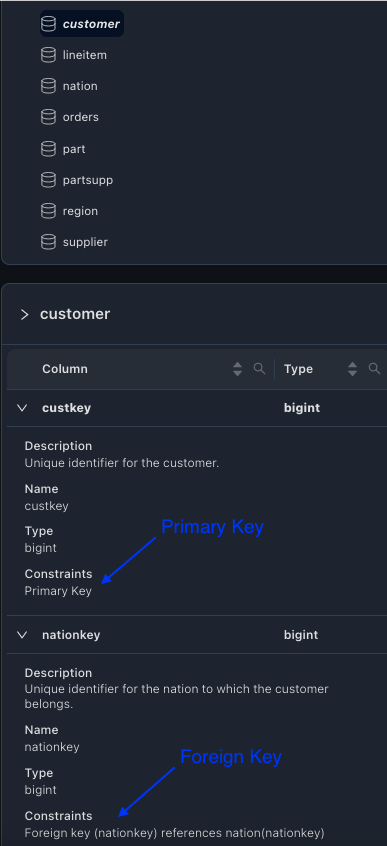
Note that Trino does not support any PK/FK definitions. We have to rely on automated analysis or user provided PK/FK for these tables. For TPC-H schema, waii's recommendations on PK/FK are accurate and PK/FK details can be viewed from the UI as well. UI will provide details on the PK/FK for each table.
PK/FK Validation Step
It is important for the users to review the PK/FK definitions for correctness. Users should review PK/FK for each table by viewing the column definitions from the UI. For e.g, User can validate if custkey can be the PK for the customer table and nationkey can be the FK for the nation table in the example given here.
If there's a need to update PK/FK for the database because the generated ones are incorrect, you can either directly update it from the database (which is preferred because it will be part of the database system). However, if the underlying database cannot be changed or doesn't support PK/FK constraint definition (such as Trino), you can use the update constraint API to update it.
Extracting Semantic Context from Documentation
(This step is optional)
It is possible to extract the documentation for the schema from file/html/url via waii cli tool. Documentation file for TPCH containing table and column descriptions is available here. Extract the file and run the following command to view the extracted details. By default CLI will not update the descriptions in the system.
waii database extract_doc --file /Users/xyz/Downloads/tpch_doc.html --doc_type html --schemas sf1
{
"semantic_context": [
{
"scope": "\"tpch\".\"sf1\".\"orders\"",
"statement": "This table stores detailed information about customer \
orders, including order dates, priorities, statuses, and total prices. \
Users can analyze order patterns, track order statuses, and calculate \
total revenue.",
"always_include": true
},
{
"scope": "\"tpch\".\"sf1\".\"orders\".orderkey",
"statement": "Unique identifier for the order (Primary Key)",
"always_include": true
},
...
...
...
]
}
You can store this output in a JSON file (e.g doc_sem_context.json) and review the output.
After reviewing the extracted documentation, you can import the semantic contexts to the system via the following command
waii database activate "trino://admin@localhost:8080/tpch"
waii context import < doc_semantic_context.json
Loaded 1 statement(s), 0 remaining
Loaded 10 statement(s), 0 remaining
...
Read 69 statement(s), imported 69 statement(s)
Running First Queries
As a sanity check, let us ask a very basic question in this schema in waii UI (http://localhost:3000/).
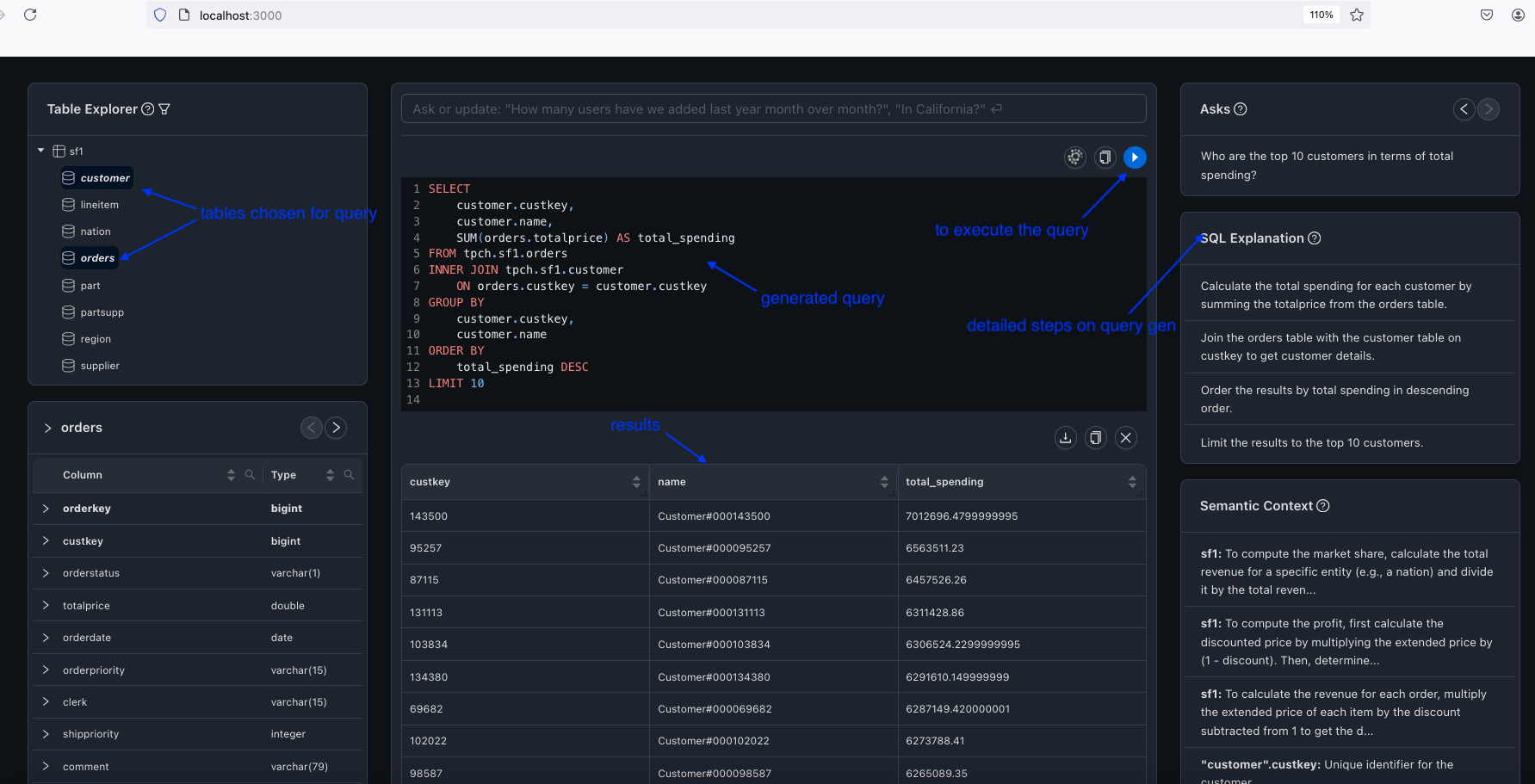
Who are the top 10 customers in terms of total spending?
This should generate the following SQL. You can run the query in the UI to view the results.
SELECT
customer.custkey,
customer.name,
SUM(orders.totalprice) AS total_spending
FROM
tpch.sf1.orders
INNER JOIN
tpch.sf1.customer ON orders.custkey = customer.custkey
GROUP BY
customer.custkey,
customer.name
ORDER BY
total_spending DESC
LIMIT 10
Higher accuracy with Train/Dev/Test sets
(This steps is Optional)
Now that we have tried out the basic queries, we can proceed to prepare the system for accuracy by splitting the available training data (question / ground truth query pairs) into the following three categories: Dev & test sets need to be just big enough to reliably determine accuracy, the other pairs should go into the train set. Common splits are 50%/25%/25%. Size of sets can range from 10s to 1000s.
Train Set
These are fed into the system as known good examples. The system will use them to learn the basic concepts of the database as well as reference them as templates for query construction.
Dev set
Dev set pairs are used to evaluate and refine the system. Failures in the query generation of dev set queries will be analyzed and semantic context will be developed to handle the identified blind spots.
Test Set
Test set is used for final confirmation and consists of questions that the system has not seen before. This helps to verify that the system has learnt about the schema and accurately generate SQL queries for a wide range of questions.
Note: The system is pre-trained and generating the sets described here is optional. If only a small set of training data is available, we recommend putting all of them into the dev set and skipping train / test. Users will through feedback complete the other aspects.
Train Set
(This steps is optional)
As with all sets we recommend that the set is reviewed for correctness (training on wrong concepts can be hard to debug later) and that the set covers as many aspects of the domain and database as possible.
There are various ways of adding queries to the training set.
- Users can provide feedback about the generated queries. Good queries will be added to the training set.
- Users can load training pairs through the API / CLI.
For the purpose of this document, we will add the pairs via API.
Download the set of question/SQL pairs from liked_queries.txt. Here is the code train.py for adding queries in liked_queries.txt. Execute as "python train.py" in the terminal.
from waii_sdk_py import WAII
from waii_sdk_py.query import LikeQueryRequest
try:
# Initialize WAII API and activate database connection
WAII.initialize(url="http://localhost:9859/api/", api_key="")
WAII.Database.activate_connection("trino://admin@localhost:8080/tpch")
# Read the file with questions and SQL queries and add them to the like queries
with open('liked_queries.txt', 'r') as f:
lines = f.readlines()
for line in lines:
question, sql = line.strip().split('^')
response = WAII.Query.like(
LikeQueryRequest(ask=question, query=sql, liked=True)
)
print(f"Added {question} to the like queries.")
except Exception as e:
print(f"Exception: {str(e)}")
Dev Set
(This steps is optional)
After running & evaluating the pairs in the dev set, there will likely be queries that weren't satisfactory. Certain questions need additional context and details about the schema to accurately generate the SQL query. To address this, we add semantic context to the system. Dev set questions help uncover the relevant semantic context needed for providing better understanding of the schema and its associated business context.
Example Scenario 1: Understanding Unshipped Orders
Business Question
What are the top 10 orders by revenue for customers in the \'BUILDING\'
market segment, where orders have been placed before March 15, 1995, but
are unshipped? Provide order details including the order key, order
date, shipping priority, and revenue.
The system generated the following SQL query to answer this question. However, it does not fully capture the metric of unshipped orders.
SELECT
orders.orderkey,
orders.orderdate,
orders.shippriority,
SUM(lineitem.extendedprice * (1 - lineitem.discount)) AS revenue
FROM
tpch.sf1.orders
INNER JOIN
tpch.sf1.customer ON orders.custkey = customer.custkey
INNER JOIN
tpch.sf1.lineitem ON orders.orderkey = lineitem.orderkey
WHERE
LOWER(customer.mktsegment) LIKE LOWER('BUILDING')
AND orders.orderdate < TRY_CAST('1995-03-15' AS DATE)
AND orders.orderstatus != 'F'
GROUP BY
orders.orderkey,
orders.orderdate,
orders.shippriority
ORDER BY
revenue DESC
LIMIT 10
Explanation and need for semantic context
By default, the system does not fully understand how to compute unshipped orders. In this context, "unshipped" means orders where the shipdate is after a certain date and the orderdate is before that date. But the system does not understand this OOTB (Out-of-the-box).
Adding Semantic Context
Here's how you can define the context for unshipped orders
- In the UI, click on "Semantic Context" in the top right corner.
- Click "Add new" button
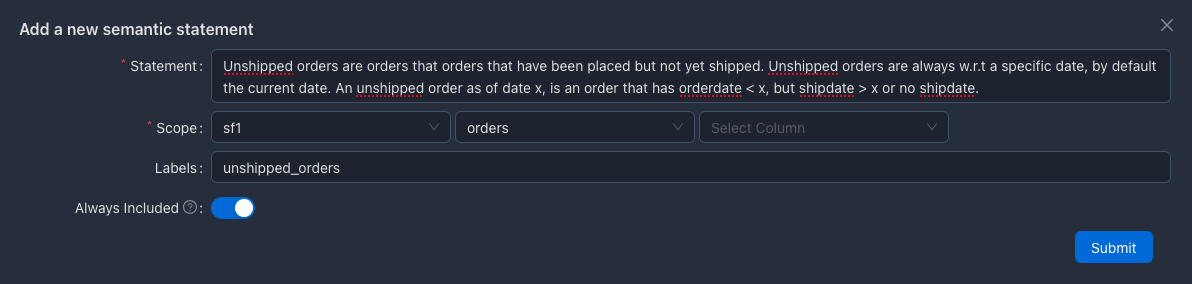
Unshipped orders are orders that orders that have been placed but not
yet shipped. Unshipped orders are always w.r.t a specific date, by
default the current date. An unshipped order as of date x, is an order
that has orderdate < x, but shipdate > x or no shipdate.
It is possible to select schema level, table level and column level scope for adding semantic contexts. In this case, we have chosen "order" table level scope in sf1 schema. Labels are an easier way to organize semantic contexts.
SQL query after adding semantic context
After adding the semantic context, the system should now correctly generate the SQL query for the given business question. Here's how the query would look with the semantic context.

By following these steps and providing the necessary semantic context, you can ensure the system accurately generates SQL queries for questions involving additional business context.
Example Scenario 2: Understanding revenue generated for items
Business Question
Generate a report of the supplier with the highest total revenue for
items shipped in the first quarter of 1996. Display supplier\'s name,
address, phone number, and total revenue.
The system generated the following SQL query to answer this question. However, it does not fully understand the revenue metric.
WITH shipped_items AS (
SELECT
suppkey,
SUM(extendedprice) AS total_revenue
FROM tpch.sf1.lineitem
WHERE
shipdate BETWEEN TRY_CAST('1996-01-01' AS DATE) AND
TRY_CAST('1996-03-31' AS DATE)
GROUP BY
suppkey
),
max_revenue AS (
SELECT MAX(total_revenue) AS highest_revenue
FROM shipped_items
)
SELECT
supplier.name,
supplier.address,
supplier.phone,
shipped_items.total_revenue
FROM shipped_items
INNER JOIN tpch.sf1.supplier
ON shipped_items.suppkey = supplier.suppkey
INNER JOIN max_revenue
ON shipped_items.total_revenue = max_revenue.highest_revenue
Explanation and need for semantic context
By default, the system does not fully understand the revenue metric. It
sums up extendedprice which is not the right way to compute the
revenue. Let us add the right semantic context for this.
Adding Semantic Context
To calculate the revenue for an order, multiply the extended price of
each item by the discount subtracted from 1 to get the discounted price,
then add up these discounted prices for all items in the order.
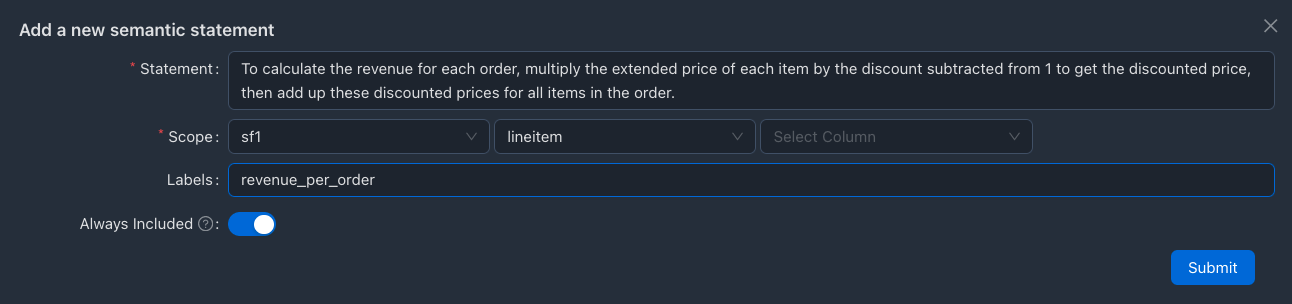
Here, we are adding the context in the table level scope (i.e SF1.lineitem), as the semantic context fits for the table and fields associated with the computation belong to the same table.
SQL query after adding semantic context
After adding the semantic context, the system should now correctly generate the SQL query for the given business question. Here's how the query would look with the semantic context.
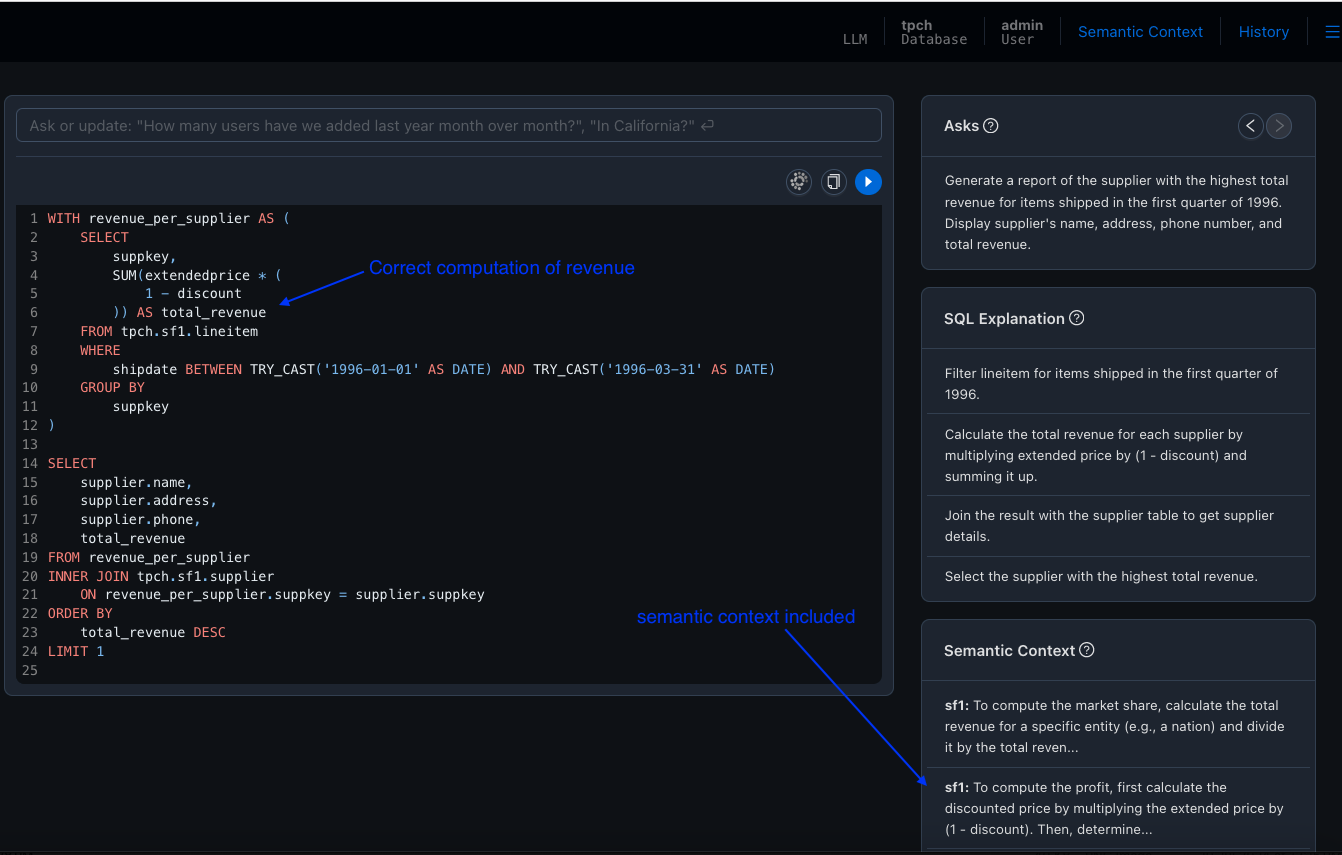
Example Scenario 3: Understanding "promotional" items
Business Question
Calculate the percentage of total revenue generated from promotional
items for orders shipped in September 1995.
The system generated the following SQL query to answer this question. However, the system refers to a 'comment' field for promotional items which is wrong.
WITH total_revenue AS (
SELECT
SUM(extendedprice * (1 - discount)) AS total_revenue
FROM tpch.sf1.lineitem
WHERE
shipdate BETWEEN TRY_CAST('1995-09-01' AS DATE) AND
TRY_CAST('1995-09-30' AS DATE)
),
promotional_revenue AS (
SELECT
SUM(lineitem.extendedprice * (1 - lineitem.discount)) AS promotional_revenue
FROM tpch.sf1.lineitem
WHERE
lineitem.shipdate BETWEEN TRY_CAST('1995-09-01' AS DATE) AND
TRY_CAST('1995-09-30' AS DATE)
AND LOWER(lineitem.comment) LIKE '%promotional%'
)
SELECT
(
promotional_revenue.promotional_revenue /
NULLIF(total_revenue.total_revenue, 0)
) * 100 AS promotional_revenue_percentage
FROM total_revenue
CROSS JOIN promotional_revenue
Explanation and need for semantic context
Promotional item information is stored in the "type" field in the "part" table. System does not understand this OOTB. This needs to be added in semantic context.
Adding Semantic Context
Promotional items are identified by looking at the type field in the
`part` table (e.g type LIKE 'PROMO%')
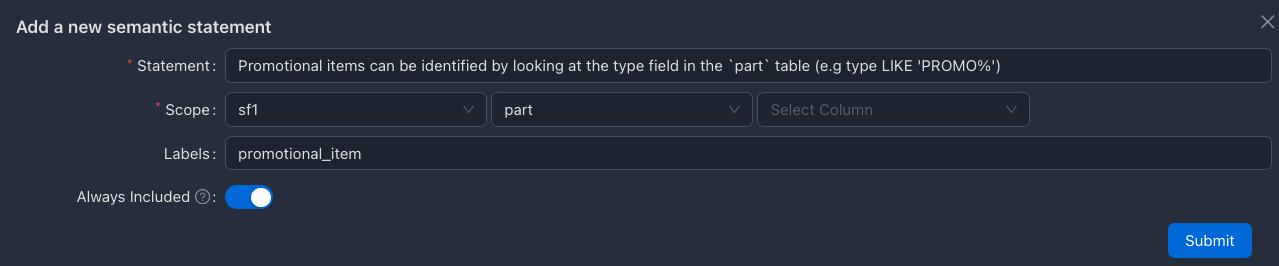
Here, we are adding the context in the table level scope (i.e SF1.part), as the semantic context fits for the table level.
#SQL query after adding semantic context
Here's how the query would look with the semantic context.
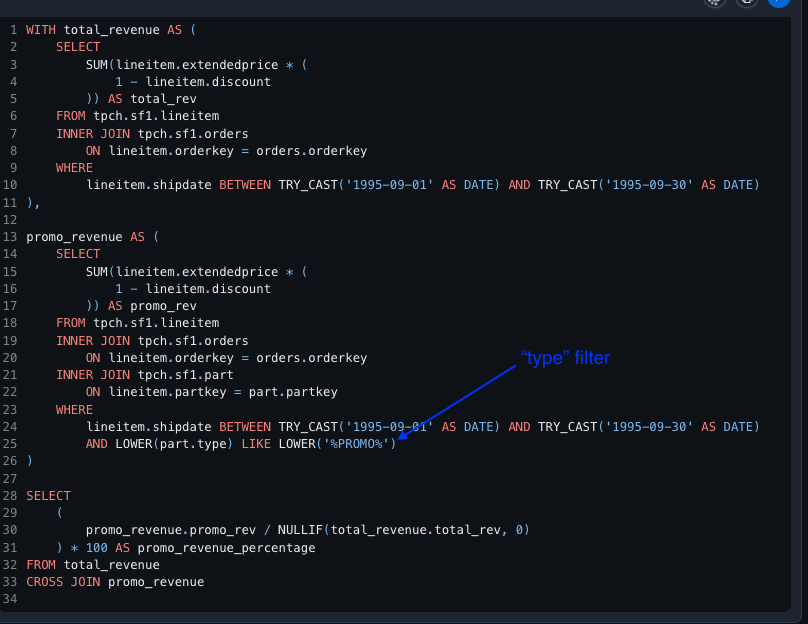
Additional semantic context
Here is some additional semantic context that can be added for the TPC-H schema. The format for these contexts is semantic context, scope, and label. When adding these contexts via the UI, you can separate them accordingly.
To compute the market share, calculate the total revenue for a specific
entity (e.g., a nation) and divide it by the total revenue for all
entities combined.
Scope: [sf1], Label: [market_share definition]
To compute the total value of each part, multiply the supply cost by the
available quantity.
Scope: [sf1.partsupp], Label: [Total_value_of_part]
Orderpriority can be one of '1-URGENT', '2-HIGH', '3-MEDIUM',
'4-NOT SPECIFIED', '5-LOW'. '1-URGENT', '2-HIGH' are considered
high priorities. '3-MEDIUM', '4-NOT SPECIFIED', '5-LOW' are
considered low priorities.
Scope: [sf1.orders.orderpriority], Label: [order_priority]
orderkey can not be joined with custkey
Scope: [sf1], Label: [join_condition validation]
To compute the profit, first calculate the discounted price by
multiplying the extended price by (1 - discount). Then, determine the
total supply cost by multiplying the supply cost by the quantity of
items. Finally, subtract the total supply cost from the discounted price
to get the profit.
Scope: [sf1], Label: [computing_profit]
Test Set
(This step is optional)
Now that we have created the "evaluation set" to help the system understand the schema and the "train set" from which the system can learn semantically equivalent queries, we are ready to proceed with the "test set." This test set will serve as the final evaluation, allowing us to assess the system's ability to generate accurate SQL queries based on its training and understanding.
Question 1
Get me a summary report of the total revenue and total discount for all
orders placed in the first quarter of 1994. Include the order date,
total revenue, and total discount for each order.
Generated Query:
WITH filtered_orders AS (
SELECT
orderkey,
orderdate
FROM tpch.sf1.orders
WHERE
orderdate BETWEEN TRY_CAST('1994-01-01' AS DATE) AND
TRY_CAST('1994-03-31' AS DATE)
)
SELECT
o.orderdate,
SUM(l.extendedprice * (1 - l.discount)) AS total_revenue,
SUM(l.discount) AS total_discount
FROM filtered_orders AS o
INNER JOIN tpch.sf1.lineitem AS l
ON o.orderkey = l.orderkey
GROUP BY
o.orderdate

System was able to detect that the new question was closely related to one of the training queries and was able to make use of it. Query detail will be visible at the bottom of the UI page, which can be loaded via the "Load Query" button for reference.

Question 2
Calculate the market share for each nation based on the total revenue
generated from orders shipped in 1995. Include the nation name and its
market share percentage
Generated Query:
WITH shipped_orders_1995 AS (
SELECT
o.orderkey,
o.custkey,
l.extendedprice * (1 - l.discount) AS revenue
FROM tpch.sf1.orders AS o
INNER JOIN tpch.sf1.lineitem AS l
ON o.orderkey = l.orderkey
WHERE
YEAR(l.shipdate) = 1995
),
nation_revenue AS (
SELECT
n.name AS nation_name,
SUM(s.revenue) AS total_revenue
FROM shipped_orders_1995 AS s
INNER JOIN tpch.sf1.customer AS c
ON s.custkey = c.custkey
INNER JOIN tpch.sf1.nation AS n
ON c.nationkey = n.nationkey
GROUP BY
n.name
),
total_revenue AS (
SELECT SUM(nation_revenue.total_revenue) AS total
FROM nation_revenue
)
SELECT
nr.nation_name,
(nr.total_revenue / NULLIF(tr.total, 0)) * 100 AS market_share_percentage
FROM nation_revenue AS nr
CROSS JOIN total_revenue AS tr
In this question, the system was able to make use of the semantic contexts related to revenue computation and market share percentage. Note that these semantic contexts were earlier as part of the evaluation set.
Question 3
Generate a report showing the total revenue for each nation in the
'EUROPE' region for orders placed in 1996. Include the nation name and
total revenue.
WITH europe_nations AS (
SELECT
nation.nationkey,
nation.name AS nation_name
FROM tpch.sf1.region
INNER JOIN tpch.sf1.nation
ON region.regionkey = nation.regionkey
WHERE
LOWER(region.name) = 'europe'
),
customer_orders AS (
SELECT
customer.custkey,
customer.nationkey,
orders.orderkey
FROM tpch.sf1.customer
INNER JOIN tpch.sf1.orders
ON customer.custkey = orders.custkey
WHERE
orders.orderdate BETWEEN TRY_CAST('1996-01-01' AS DATE) AND
TRY_CAST('1996-12-31' AS DATE)
),
nation_orders AS (
SELECT
europe_nations.nation_name,
customer_orders.orderkey
FROM europe_nations
INNER JOIN customer_orders
ON europe_nations.nationkey = customer_orders.nationkey
)
SELECT
nation_orders.nation_name,
SUM(lineitem.extendedprice * (1 - lineitem.discount)) AS total_revenue
FROM nation_orders
INNER JOIN tpch.sf1.lineitem
ON nation_orders.orderkey = lineitem.orderkey
GROUP BY
nation_orders.nation_name
Generated query makes use of the semantic context related to total revenue generation. Ground truth query for this question is given below.
SELECT
nation.name AS nation_name,
SUM(lineitem.extendedprice * (1 - lineitem.discount)) AS total_revenue
FROM
tpch.sf1.nation
INNER JOIN tpch.sf1.customer
ON nation.nationkey = customer.nationkey
INNER JOIN tpch.sf1.orders
ON customer.custkey = orders.custkey
INNER JOIN tpch.sf1.lineitem
ON orders.orderkey = lineitem.orderkey
INNER JOIN tpch.sf1.region
ON nation.regionkey = region.regionkey
WHERE
LOWER(region.name) = 'europe'
AND orders.orderdate BETWEEN TRY_CAST('1996-01-01' AS DATE) AND
TRY_CAST('1996-12-31' AS DATE)
GROUP BY
nation.name
ORDER BY
total_revenue DESC
Question 4
Generate a report of the total annual profit for each nation for orders
placed in years where the part name includes \'green\'. Provide the
total profit for each nation and year, sorted by nation and year
Generated Query:
WITH filtered_parts AS (
SELECT partkey
FROM tpch.sf1.part
WHERE
LOWER(name) LIKE '%green%'
),
lineitem_profit AS (
SELECT
l.orderkey,
l.extendedprice * (1 - l.discount) - ps.supplycost * l.quantity AS profit
FROM tpch.sf1.lineitem AS l
INNER JOIN tpch.sf1.partsupp AS ps
ON l.partkey = ps.partkey AND l.suppkey = ps.suppkey
WHERE
l.partkey IN (
SELECT filtered_parts.partkey
FROM filtered_parts
)
),
order_profit AS (
SELECT
o.orderkey,
o.orderdate,
c.nationkey,
lp.profit
FROM tpch.sf1.orders AS o
INNER JOIN lineitem_profit AS lp
ON o.orderkey = lp.orderkey
INNER JOIN tpch.sf1.customer AS c
ON o.custkey = c.custkey
),
nation_profit AS (
SELECT
n.name AS nation_name,
YEAR(o.orderdate) AS order_year,
SUM(o.profit) AS total_profit
FROM order_profit AS o
INNER JOIN tpch.sf1.nation AS n
ON o.nationkey = n.nationkey
GROUP BY
n.name,
YEAR(o.orderdate)
)
SELECT
nation_profit.nation_name,
nation_profit.order_year,
nation_profit.total_profit
FROM nation_profit
ORDER BY
nation_profit.nation_name,
nation_profit.order_year
In case you have a large set of dev/training/test questions, you can consider using archerfish benchmark, which is a benchmarking framework designed for evaluating the capabilities of NL2SQL systems.
Appendix
Trino Docker Image
mkdir -p ~/trino/etc/catalog
mkdir -p /Users/<user_name>/Downloads/trino/data
docker pull trinodb/trino
create tpch.properties in ~/trino/etc/catalog/tpch.properties with following content:
connector.name=tpch
start docker container for trino
docker run --name trino -d -p 8080:8080 -v ~/trino/etc:/etc/trino -v
/Users/<user_name>/Downloads/trino/data:/var/trino/data trinodb/trino
Use trino client to verify
docker exec -it trino trino
trino> show catalogs;